Meta Robots 标签优化全攻略・精准控制抓取,助力网站 SEO 排名
在前端 SEO 优化中,除了内容、结构、速度等核心维度,对搜索引擎爬虫的精准控制同样决定了网站的索引效率与排名效果。Meta Robots 标签作为页面级的爬虫控制指令,无需修改服务器配置,直接通过 HTML 头部即可生效,是前端开发者最易上手、最常用的爬虫管控工具。
本文将从 Meta Robots 标签的基础定义、语法写法,到与 Robots.txt 的核心区别,再到进阶指令、HTTP 头配置、实战优化场景与避坑指南,全面拆解 Meta Robots 标签的使用逻辑,帮你实现对页面抓取、索引、展示的精细化控制,规避 SEO 风险,放大流量价值。
什么是 Meta Robots 标签
基础定义
Meta Robots 是放置在 HTML <head> 标签内的元标签,用于向搜索引擎爬虫(如 Google、百度、必应)发送页面级指令,告知爬虫是否允许抓取当前页面、是否将页面加入索引、是否追踪页面内链接等。
它是页面级控制规则,仅对当前页面生效,与站点的 Robots.txt 协议作用环节完全不同。
核心作用
- 控制页面是否被搜索引擎索引
- 控制页面内链接是否被爬虫追踪抓取
- 禁止搜索引擎缓存页面、展示摘要
- 避免重复内容、低价值页面占用爬虫资源
- 保护隐私页面、测试页面不被曝光
- 控制搜索结果中的页面展示形式(如摘要长度、图片预览大小)
如何使用 Meta Robots 标签(基础语法)
标准写法
Meta Robots 标签固定写在 <head> 中,语法格式:
1 | <meta name="robots" content="指令1,指令2"> |
name="robots":适配所有主流搜索引擎- 如需针对单一引擎,可改为
googlebot/baiduspider/bingbot content:填写控制指令,多指令用英文逗号分隔,无顺序要求
核心指令含义
| 指令 | 作用 |
|---|---|
index |
允许搜索引擎索引当前页面(默认值,可省略) |
noindex |
禁止索引当前页面(已抓取的页面会逐渐从索引中移除) |
follow |
允许追踪页面内的链接(默认值,可省略),传递链接权重 |
nofollow |
禁止追踪页面内的链接,不传递权重 |
noarchive |
禁止搜索引擎缓存页面快照(如 Google 的“网页快照”) |
nosnippet |
禁止在搜索结果中展示页面摘要,仅显示标题和 URL |
noimageindex |
禁止索引页面中的图片(图片不会出现在图片搜索结果中) |
进阶指令:控制搜索结果展示
除了核心抓取/索引指令,现代搜索引擎还支持控制搜索结果展示形式的进阶指令,提升用户点击率:
max-snippet:[数字]:限制搜索结果摘要的最大字符数(如max-snippet:150)max-image-preview:[size]:控制图片预览大小,可选值:none(无预览)、standard(标准预览)、large(大预览)max-video-preview:[数字]:控制视频预览的最大秒数(如max-video-preview:10)
示例:限制摘要长度为 100 字符,允许大图片预览:
1 | <meta name="robots" content="index,follow,max-snippet:100,max-image-preview:large"> |
常用组合
- 全站通用(允许索引+追踪链接)
1 | <meta name="robots" content="index,follow"> |
- 禁止索引(隐私/测试页,但保留链接追踪)
1 | <meta name="robots" content="noindex,follow"> |
- 禁止索引+禁止追踪(低价值页/404页)
1 | <meta name="robots" content="noindex,nofollow"> |
- 控制展示形式(核心流量页)
1 | <meta name="robots" content="index,follow,max-snippet:200,max-image-preview:large"> |
补充:X-Robots-Tag HTTP 头
除了 HTML 中的 Meta Robots 标签,还可以通过HTTP 响应头发送爬虫指令,适合无法修改 HTML 的场景(如 PDF、图片、视频文件,或动态生成的非 HTML 资源)。
配置方法
Apache(.htaccess 文件)
1 | # 对所有 PDF 文件设置 noindex |
Nginx(配置文件)
1 | # 对所有图片文件设置 noimageindex |
与 Meta Robots 标签的关系
- 两者作用等价,优先级相同(若同时存在,所有指令都会生效,冲突时以最严格的为准)
- HTTP 头可用于非 HTML 资源,Meta 标签仅用于 HTML 页面
Robots.txt 与 Robots Meta Tag 的区别
很多开发者会混淆站点级 Robots.txt 和页面级 Meta Robots,二者核心差异如下:
| 维度 | Robots.txt | Meta Robots 标签 / X-Robots-Tag |
|---|---|---|
| 作用范围 | 站点/目录级,全局生效 | 页面/资源级,仅当前对象生效 |
| 控制逻辑 | 告诉爬虫能不能来抓取(阻止访问) | 告诉爬虫抓取后能不能索引/展示(允许访问但限制后续操作) |
| 优先级 | 低 | 高(页面标签可覆盖 txt 规则) |
| 生效方式 | 服务器根目录文件 | HTML 头部代码 / HTTP 响应头 |
| 适用场景 | 屏蔽目录、限制爬虫爬取频率 | 控制单页面索引、链接追踪、搜索展示 |
关键结论:
Robots.txt 是门禁,阻止爬虫访问;
Meta Robots 是内部规则,允许爬虫访问,但限制索引/展示。
⚠️ 注意:若 Robots.txt 禁止抓取页面,爬虫根本不会读取页面上的 Meta Robots 标签,因此无法通过 noindex 让已被 Robots.txt 屏蔽的页面从索引中移除(需先允许抓取,再用 noindex)。
Meta Robots 标签优化原则
高价值页面:全开权限+优化展示
首页、栏目页、文章详情页、产品页等核心流量页,必须配置:
1 | <meta name="robots" content="index,follow,max-image-preview:large"> |
保证爬虫充分抓取、索引、传递权重,同时优化搜索结果展示形式。
低价值页面:禁止索引
- 搜索结果页、分页重复页、TAG 空页面
- 后台、登录页、隐私政策、用户中心
- 测试页、临时页面、重复内容页
统一配置noindex(若页面内有有用链接,可保留follow传递权重),避免浪费爬虫配额,降低网站整体质量。
非 HTML 资源:按需控制
- PDF 文档:若为公开资料,允许索引;若为内部资料,设置
noindex - 图片:核心产品图允许索引,装饰性图片可设置
noimageindex - 视频:按需设置预览时长
避免致命错误
- 不要给核心页面加
noindex:会导致页面从索引中移除,流量暴跌 - 不要全站统一用同一种指令:需按页面价值差异化配置
- 指令拼写错误:如
no-index、no follow(带连字符或空格)会导致规则失效 - 移动端/PC 端页面标签不一致:若有独立移动端页面,需保持 Meta Robots 标签一致,避免冲突
- Robots.txt 与 Meta Robots 矛盾:如 Robots.txt 禁止抓取,Meta Robots 却设置
index,会导致index无效
常见误区与诊断方法
常见误区
- 用 Robots.txt 屏蔽重复内容:Robots.txt 只能阻止抓取,不能阻止索引(若其他页面链接到该页面,仍可能被索引),正确做法是用
noindex - 对 404 页面设置
noindex:404 页面本身不会被索引,无需额外设置,但可设置nofollow避免追踪无效链接 - 滥用
nofollow:内部链接无需设置nofollow(会浪费内部权重传递),仅对广告链接、不可信的外部链接使用 - 页面存在多个 Meta Robots 标签时:搜索引擎会合并所有指令,冲突时以最严格的规则为准
诊断方法
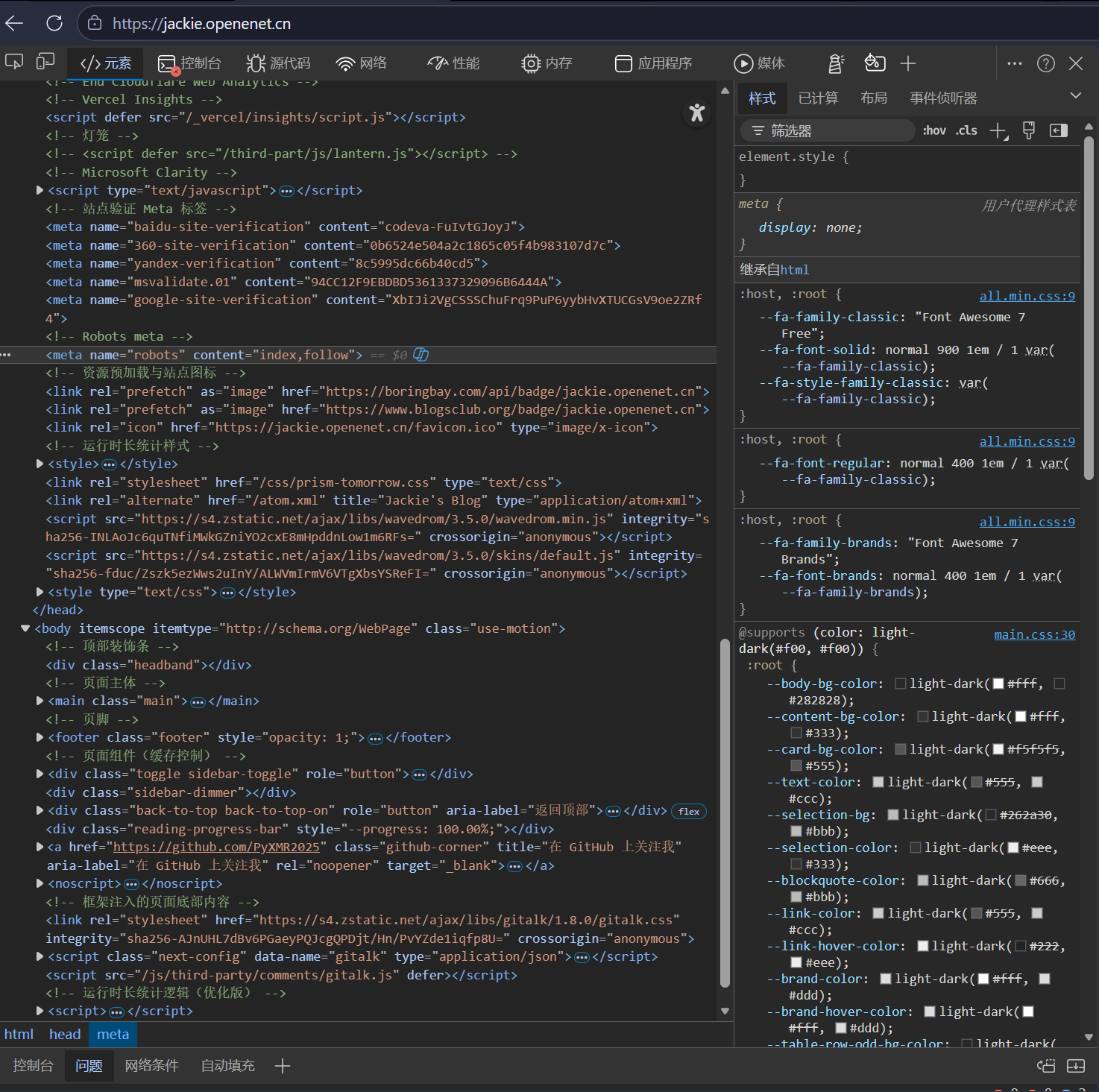
- 浏览器开发者工具:打开页面 → 右键“查看网页源代码” → 检查
<head>中的 Meta Robots 标签
查看网页源代码截图
- HTTP 头检查工具:使用 Redirect Checker 或浏览器开发者工具的“网络”面板,查看 X-Robots-Tag 响应头
- Google Search Console:使用“URL 检查工具”,查看 Google 对页面的抓取/索引状态,确认 Meta Robots 标签是否生效
- 百度搜索资源平台:使用“抓取诊断”工具,检查百度爬虫对页面的识别情况
动态页面的 Meta Robots 处理
对于 SPA(单页应用)、动态生成的页面,需通过 JavaScript 动态设置 Meta Robots 标签,确保爬虫抓取到正确的指令。
示例:Vue.js 中动态设置
1 | // 在路由守卫或组件 mounted 中设置 |
⚠️ 注意:确保爬虫能渲染 JavaScript(Google 爬虫支持,百度爬虫需额外验证),或使用预渲染/服务端渲染(SSR)技术。
实战应用场景与案例
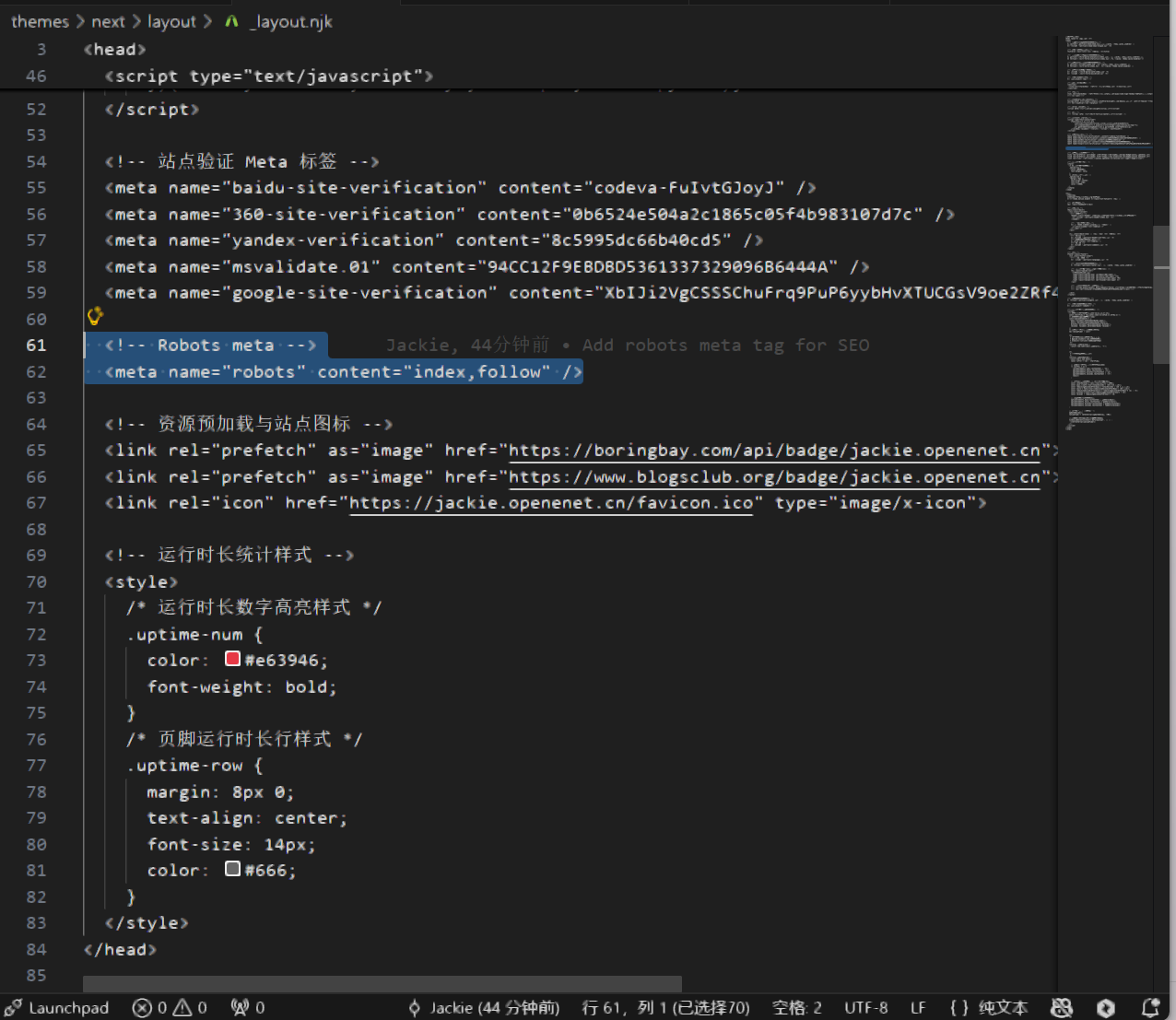
博客文章详情页(核心流量页)
1 | <meta name="robots" content="index,follow,max-snippet:200,max-image-preview:large"> |
允许索引,追踪内链传递权重,优化搜索结果展示。
NexT 主题博客修改截图
网站搜索结果页/分页页
1 | <meta name="robots" content="noindex,follow"> |
禁止索引,避免重复内容,但保留链接追踪,让爬虫能通过分页找到更多文章。
隐私政策/404 页面
1 | <meta name="robots" content="noindex,nofollow"> |
完全禁止索引与链接追踪,避免浪费爬虫资源。
PDF 文档(公开资料)
通过 X-Robots-Tag 设置:
1 | # Apache 配置 |
允许索引 PDF,但禁止缓存快照。
真实案例:从流量暴跌到恢复
某电商网站因改版错误,给所有产品页加上了 noindex,导致一周内有机流量下降 70%。
修复步骤:
- 移除所有产品页的
noindex指令,恢复index,follow - 在 Google Search Console 中提交所有产品页的 URL 重新抓取
- 优化产品页的 Meta Robots 进阶指令(
max-image-preview:large)
结果:两周内流量恢复 80%,一个月后超过改版前水平。
不同搜索引擎的支持情况
| 指令 | 百度 | 必应 | |
|---|---|---|---|
index/noindex |
✅ | ✅ | ✅ |
follow/nofollow |
✅ | ✅ | ✅ |
noarchive |
✅ | ✅ | ✅ |
nosnippet |
✅ | ✅ | ✅ |
noimageindex |
✅ | ✅ | ✅ |
max-snippet |
✅ | ❌ | ✅ |
max-image-preview |
✅ | ❌ | ✅ |
max-video-preview |
✅ | ❌ | ✅ |
💡 提示:百度对进阶指令支持有限,核心优化仍以 index/noindex、follow/nofollow 为主。
总结
Meta Robots 标签是前端 SEO 的精细化控制工具,核心价值在于把优质页面推给搜索引擎,把低价值页面隔离出去。
- 它是页面级指令,优先级高于 Robots.txt,配合 X-Robots-Tag 可覆盖所有资源类型
- 核心掌握
index/noindex、follow/nofollow四大基础指令,善用进阶指令优化搜索展示 - 按页面价值差异化配置,不盲目统一规则,避免致命错误
- 结合站点结构、内容质量,配合 Robots.txt、站点地图等其他 SEO 手段,才能最大化抓取与索引效率
- 定期通过搜索资源平台诊断标签生效情况,及时修复问题
对于前端开发、独立博客、站点运维而言,吃透 Meta Robots 标签,就能用最简单的代码,实现对搜索引擎爬虫的精准管控,为网站 SEO 排名打下坚实基础。